WebAssembly实践
本文于 1407 天之前发表,文中内容可能已经过时。
前言
JavaScript 最初被设计出来的时候,作者一定想不到 Web 会发展到今天的规模。随着前端技术发展,浏览器端应用越来越复杂,JavaScript的性能问题逐渐突出。Chrome的 V8 引擎对 JavaScript 预编译速度做了极大提升,但这还不够。因为 JavaScript的动态类型特性,始终无法回避类型推断。要进一步提高 Web端应用的性能,开发者向其它方向做出了努力,那就是向强类型靠近,彻底避免类型推断。前有Mozilla 的 asm.js,后有 Google 的NaCl,今有四大浏览器(Chrome/Firefox/Edge/Safari)厂商联手推出的 WebAssembly。自2017年11月四大浏览器开始全面支持 WebAssembly以来,WebAssembly 获得了广泛应用和更多关注。酷家乐几何中间件团队对WebAssembly 进行了一些实验,得到一些很有实践意义的结论。
本文重点讨论如何实践,过于细节的机制和原理等内容不在本文讨论范围内。如想了解更多细节,请关注几何中间件团队的WebAssembly 后续文章,或查阅文末给出的参考文献。
概念
WebAssembly 按字面意思可理解为 Web 的汇编语言。事实上,WebAssembly正是一种二进制文件格式的定义,类似汇编。从一个例子来了解 WebAssembly的汇编性质,以 C 为例(接下来的讨论也均基于 C语言,但事实上有多种语言均可被编译为WebAssembly)。
int square (int x) {
return x * x;
}这个函数编译成 WebAssembly 就变成了二进制。如果你打开 *.wasm文件,会看到这样的结果:
....7279 4261 7365 037f 0003 656e 7609 7461626c 6542 6173 6503 7f00 0365 6e76 08535441 434b 544f 5003 7f00 0365 6e76 09535441 434b 5f4d 4158 037f 0003 656e 7612...其实,WebAssembly 也提供了一种可读的文本描述模式WAST,可在编译时通过编译选项输出 *.wast 文件。如果打开 *.wast文件,可以看到如下文本(在实践中,没有必要单独输出 wast 文件,在 VSCode里装个名为 WebAssembly 的插件,右键点击 wasm
文件就可以看到这样的文本):
(func $_square (type $t1) (param $p0 i32) (result i32)
(local $l0 i32) (local $l1 i32) (local $l2 i32) (local $l3 i32) (local $l4 i32) (local $l5 i32)
get_global $g4
set_local $l5
get_global $g4
i32.const 16
i32.add
set_global $g4
get_global $g4
get_global $g5
i32.ge_s
if $I0
i32.const 16
call $env.abortStackOverflow
end
get_local $p0
set_local $l0
get_local $l0
set_local $l1
get_local $l0
set_local $l2
get_local $l1
get_local $l2
i32.mul
set_local $l3
get_local $l5
set_global $g4
get_local $l3
return)不知道什么意思,但看起来有点像 x86 汇编的 ADD、MOV、MUL 那些指令。因为这样的汇编码几乎是不可读的,也使得 WebAssembly 在一定程度上有了加密的功能。
编译
WebAssembly 是从何处、何种语言得到的?它可以由多种语言通过编译器
Emscripten 编译到 LLVM,然后生成 WebAssembly。
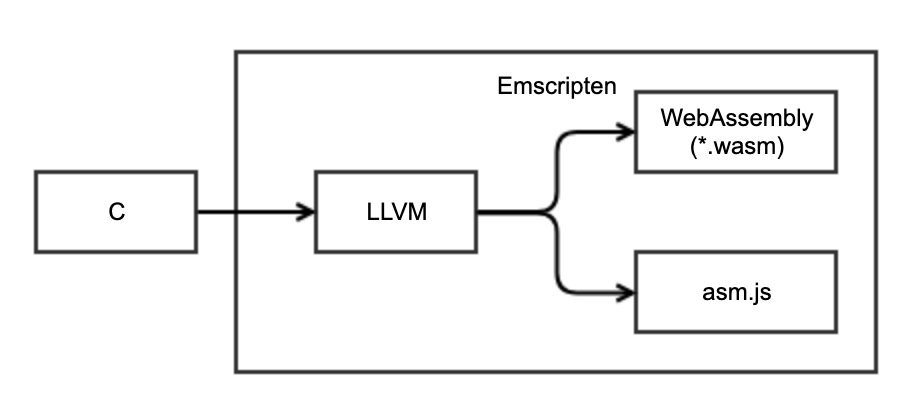
没错,Emscripten 这个编译器还可以产出asm.js,这也是它最初的用途。在编译时,使用不同的编译指令可以生成不同的产出物。
环境
在开始实践之前,首先要配好环境。安装和配置 Emscripten的步骤可参考这篇文档,写得非常详细。事实上,安装和配置Emscripten 比较复杂,且下载的各种包基本都需要翻墙,也可使用一些在线的IDE 去完成编译这个步骤,比如这个网站。
一旦编译成功后,就不再需要特殊环境,只要浏览器支持 WebAssembly就可以运行了。
实验
我们以一个比较常见的应用场景作为背景来讨论代码怎么写、怎么编译、怎么调用。这个应用场景就是:把数学计算抽离出来作为库函数,编译成WASM 供业务代码调用。
这里先提供一个名为 loadWasm 的加载方法,以下 Demo 中调用的 loadWasm均是这个方法。暂时不需要知道它具体每一步在做什么,只需知道它根据一个 wasm 文件生成一个 WebAssembly 实例。
function loadWasm(fileName) {
return fetch(fileName).then(response => {
return response.arrayBuffer().then(bytes => {
return WebAssembly.compile(bytes).then(module => {
const imports = {
env: {
abortStackOverflow: () => { throw new Error('overflow'); },
memoryBase: 0,
tableBase: 0,
memory: new WebAssembly.Memory({ initial: 256, maximum: 256 }),
table: new WebAssembly.Table({ initial: 0, maximum: 0, element: 'anyfunc' }),
STACKTOP: 0,
STACK_MAX: memory.buffer.byteLength,
}
};
return WebAssembly.instantiate(module, imports || {});
});
});
});
}示例1 - 整型I/O
假设要提供一个整型数字的平方的计算公式。用 C 语言写一个函数,只有三行:
int square (int x) {
return x * x;
}保存,命名为 math.c,这样就有了一个捉襟见肘的数学库。
在当前工作目录下编译,指令是:
emcc math.c -s ONLY_MY_CODE=1 -s EXPORTED_FUNCTIONS="['_square']" -o math.js注意函数名 square 前有下划线。编译选项中,第一个参数 math.c 指源文件,-o指输出路径及文件名,其它参数前均需加 -s。其它参数中,ONLY_MY_CODE 表示不要加入额外内容(如下文的 RUNTIME 方法 ccall 和 cwrap),EXPORTED_FUNCTIONS 表示要导出的方法(不声明则不会被导出,也就不能通过Module.exports 找到并调用)。编译成功后可以得到两个文件 math.wasm 和math.js。js文件无用,可以认为这是编译器的一些早期遗留规则所致,我们只需要 math.wasm即可,下文皆如此。
接下来在 JavaScript 中调用。加载 math.wasm 并使用其导出的方法 square:
loadWasm('math.wasm').then(Module => {
const result = Module.exports._square(2);
console.log(result);
});可以看到控制台输出 4。如果把 2 改成 2.9,仍然输出4。这可以很好地说明两种语言间的类型约定:不管传进来什么值,C语言函数规定了输入值是 int,输入的值就一定会被转换成 int。
为了让数学库稍微丰满一点,向 math.c 再加一个计算 10 以内阶乘的方法:
int factorial (int x) {
if (x > 10) {
return -1;
} else if (x < 2) {
return x;
} else {
return x * factorial(x-1);
}
}重新编译:
emcc math.c -s ONLY_MY_CODE=1 -s EXPORTED_FUNCTIONS="['_square','_factorial']" -o math.js编译指令与之前唯一的区别在于导出的函数中增加了 _factorial。
示例2 - C引用标准库函数
刚才的阶乘计算含不友好,超过限制返回 -1。加一行提示修改成下面的样子:
... ...
if (x > 10) {
printf("The given number is far too large.\n");
return -1;
}
... ...为了使用 printf 函数,需要引入标准 io 库。在 math.c 第一行加入:
#include <stdio.h>这次用另一种方式编译:
emcc math.c -s EXPORTED_FUNCTIONS="['_square','_factorial']" EXTRA_EXPORTED_RUNTIME_METHODS="['_ccall','_cwrap']" -o math.js我们去除了 ONLY_MY_CODE,因为需要 ccall 和 cwrap。有没有发现 stdio.h是不需要编译的?头文件只是声明而不是定义,无需被编译。
这次不再直接通过 Module.exports.factorial 调用阶乘方法,而用 cwrap 对factorial 方法进行包装,调用包装后的阶乘方法。cwrap的三个参数分别是方法名、返回类型定义、参数列表类型定义,均为字符串。
var factorial = Module.cwrap('factorial', 'number', ['number']);
factorial(11);这时候会看到控制台输出 “The given number is far too
large.”。注意,如果在 C 中没有写换行符 \n,则不会输出任何内容。
示例3 - 编译多个文件
我们的数学库现在有两个函数,太大了,想拆分成两个文件,一个叫square.c,一个叫 factorial.c,难道要分别编译出两个 wasm文件然后分别引用吗?太麻烦太浪费了。可以编译成一个 wasm 文件。
emcc sqaure.c -o square.bc
emcc factorial.c -o factorial.bc
emcc sqaure.bc factorial.bc -s ONLY_MY_CODE=1 -s EXPORTED_FUNCTIONS="['_square','_factorial']" -o math.js示例4 - 编译多个文件时使用标准库函数
你应该已经猜到编译指令是什么了。
emcc sqaure.bc factorial.bc -s EXPORTED_FUNCTIONS="['_square','_factorial']" EXTRA_EXPORTED_RUNTIME_METHODS="['_ccall','_cwrap']" -o math.jsDemo 5 - 引用类型
刚才举例的方法中输入输出都是值类型,如果是引用类型怎么办?举例来说,如何对一个三维向量进行单位化计算?
三维向量的结构体定义:
struct Vector3 {
double x;
double y;
double z;
};C 语言中的单位化方法声明:
Vector3* normalize(Vector3* v);编译后,在 JavaScript 端怎么去调用?可以猜测一下,对于引用类型的数据,需要有一份共享内存,使得两种语言都可以访问同一份数据。以 Vector3 数据为例,它在 C 中被定义,要求 xyz 皆是 double。double类型在内存中实际占用 4 个字节,因此它在 JavaScript 中也应占用 4 个字节。在 JavaScript 端使用 TypedArray 定义强类型,与 double对应的类型是 Float32。具体的对应规则可自行查阅资料。
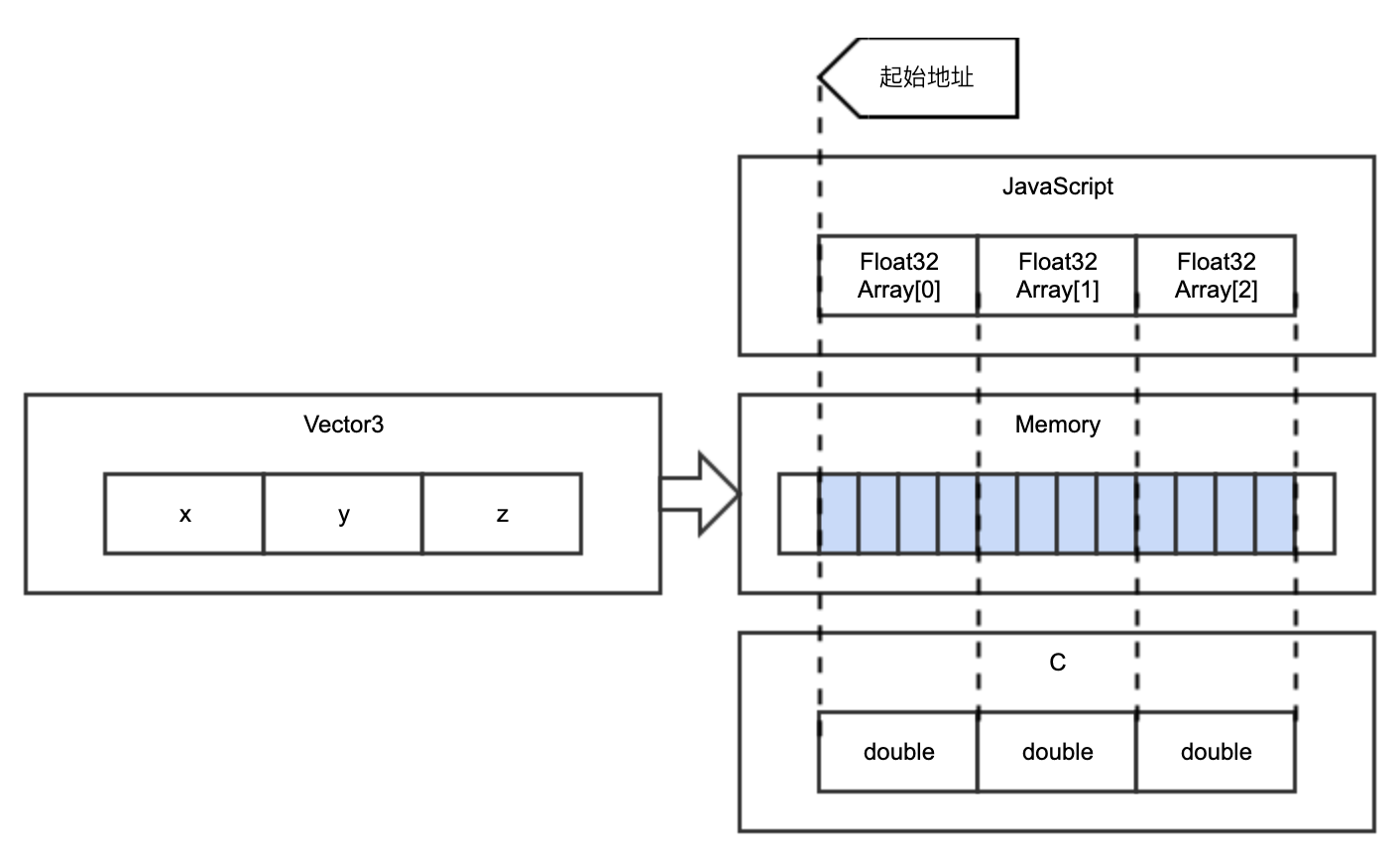
在 JavaScript 端用 cwrap 去包装一下,输入输出均定义为 Object。
var normalizeWrapper = Module.cwrap('normalize', 'Object', ['Object']);可以预见调用 C 语言的 normalize 方法会有很多细节问题,所以我们在 cwrap包装后再包装一道,提前准备一个名为 normalize的方法,往这个方法里面填充内容。在这个方法里,首先准备输入数据,然后调用normalizeWrapper 做计算,接下来处理输出数据,最后返回。
var normalize = function (v) {
// 1. 准备输入数据v -> _v
// 2. 调用normalizeWrapper(_v)
// 3. 处理输出数据_vNormalized -> vNormalized
// 4. 返回vNormalized
}首先,准备输入数据。构造一个 Float32Array,把 xyz的值放进去。这样不管放进去的是什么值,都会当作 double 类型来处理。
// 1.1
var _v = new Float32Array(3);
_v[0] = v.x;
_v[1] = v.y;
_v[2] = v.z;这个结构化的数据 _v 应当放入 JavaScript 和 WebAssembly共享的内存之中。放在哪?类似 C 的 malloc,通过 Module 申请一块长度为 3的内存,把 _v 放进去。这里 malloc 申请了 3 个 4 字节的内存空间、_vAddr右移两位等于 _vAddr/4,都是因为每个 double 数值都占 4 个字节。
// 1.2
var _vAddr = Module._malloc(4 * 3);
Module.HEAPF32.set(_v, _vAddr >> 2);调用 normalizeWrapper 计算。
// 2.
var _vNormalizedAddr = normalizeWrapper(_vAddr);返回的值 _vNormalizedAddr仍然是个内存地址,需要根据它的内容去找结果的值在哪里、以及值是什么。显然,取数据与放数据时相反的操作:先根据返回的内存地址定位一块内存,然后按照每个double 值占 4 个字节的偏移依次找到 xyz。
// 3.
var view = new DataView(Module.HEAPF32.buffer.slice(_vNormalizedAddr));
var xNormalized = view.getFloat32(0, true);
var yNormalized = view.getFloat32(4, true);
var zNormalized = view.getFloat32(8, true);现在得到了结果,直接返回就可以了吗?不!WebAssembly需要手动回收内存。为了让程序不莫名其妙地崩溃,必须像 C/C++那样认真回收每一块内存。这里默认 normalize 方法返回一个新的 Vector3的实例,而不是修改已有的三维向量,所以两个实例占用的内存空间都需要释放。
// 4.
Module._free(_vAddr);
Module._free(_vNormalizedAddr);
var v = new Vector3(xNormalized, yNormalized, zNormalized);
return v;综合以上 4 个步骤,JavaScript 端完整的 normalize 方法应该是这样的:
var normalize = function (v) {
var _v = new Float32Array(3);
_v[0] = v.x;
_v[1] = v.y;
_v[2] = v.z;
var _vAddr = Module._malloc(4 * 3);
Module.HEAPF32.set(_v, _vAddr >> 2);
var _vNormalizedAddr = normalizeWrapper(_vAddr);
var view = new DataView(Module.HEAPF32.buffer.slice(_vNormalizedAddr));
var xNormalized = view.getFloat32(0, true);
var yNormalized = view.getFloat32(4, true);
var zNormalized = view.getFloat32(8, true);
Module._free(_vAddr);
Module._free(_vNormalizedAddr);
var v = new Vector3(xNormalized, yNormalized, zNormalized);
return v;
}值得注意的是,变量在内存中的顺序以 C 结构体声明的顺序排序。如果在 C 中
Vector3 是这样声明的:
struct Vector3 {
double y;
double z;
double x;
};那么向 TypedArray 放入值时应该按照 yzx的顺序依次放入,在取出值时也应按照 yzx 的顺序读回。
示例 X
有了以上几个 示例 的经验,已经可以处理绝大部分数据结构。对于那些层层嵌套的引用类型,也能如法炮制共享内存。像下面这种嵌套混合值类型和引用类型的结构,只要依次构造 TypedArray 并按顺序放进内存即可(仅为举例,结构并不合理,且以 Vector3 代替“点”的定义)。
struct Rectangle {
int id; // 编号
Vector3 vertices[4]; // 4个顶点
Vector3 normal; // 法线
double square; //面积
}人肉写数据转换的过程中,想不想有个自动化工具来帮你……
// 1. id 注意int在不同编译器下字长不同,在C中用sizeof看一下最可靠
var _id = new Int32Array(1);
_id[0] = rectangle.id;
var _idAddr = Module.malloc(4 * 1);
Module.HEAP32.set(_id, _idAddr >> 2);
// 2. vertices
var _vertex0 = new Float32Array(3);
_vertex0[0] = rectangle.vertices[0].x;
_vertex0[1] = rectangle.vertices[0].y;
_vertex0[2] = rectangle.vertices[0].z;
var _vertex0Addr = Module.malloc(4 * 3);
Module.HEAPF32.set(_vertex0, _idVertex0Addr >> 2);
var _vertex1 = new Float32Array(3);
_vertex1[0] = rectangle.vertices[0].x;
_vertex1[1] = rectangle.vertices[0].y;
_vertex1[2] = rectangle.vertices[0].z;
var _vertex1Addr = Module.malloc(4 * 3);
Module.HEAPF32.set(_vertex1, _idVertex1Addr >> 2);
var _vertex2 = new Float32Array(3);
_vertex2[0] = rectangle.vertices[0].x;
_vertex2[1] = rectangle.vertices[0].y;
_vertex2[2] = rectangle.vertices[0].z;
var _vertex2Addr = Module.malloc(4 * 3);
Module.HEAPF32.set(_vertex2, _idVertex2Addr >> 2);
var _vertex3 = new Float32Array(3);
_vertex3[0] = rectangle.vertices[2].x;
_vertex3[1] = rectangle.vertices[2].y;
_vertex3[2] = rectangle.vertices[2].z;
var _vertex3Addr = Module.malloc(4 * 3);
Module.HEAPF32.set(_vertex3, _idVertex3Addr >> 2);
var _vertex0Addr = Module._malloc(4 * 3);
var _vertex1Addr = Module._malloc(4 * 3);
var _vertex2Addr = Module._malloc(4 * 3);
var _vertex3Addr = Module._malloc(4 * 3);
var _vertices = new UInt32Array(4);
_vertices[0] = _vertex0Addr;
_vertices[1] = _vertex1Addr;
_vertices[2] = _vertex2Addr;
_vertices[3] = _vertex3Addr;
var _verticesAddr = Module.malloc(4 * 4);
Module.HEAPU32.set(_vertices, _verticesAddr >> 2);
// 3. normal
var _normal = new Float32Array(3);
_normal[0] = triangle.normal.x;
_normal[1] = triangle.normal.y;
_normal[2] = triangle.normal.z;
var _normalAddr = Module.malloc(4 * 3);
Module.HEAPF32.set(_normal, _normalAddr >> 2);
// 4. square
var _square = new Float32Array(1);
_square[0] = rectangle.square;
var _squareAddr = Module.malloc(4 * 1);
Module.HEAPF32.set(_square, _squareAddr >> 2);事实上,有一些第三方工具如 Embind、WebIDL 来代为处理数据类型共享与转换。在函数库较大的情况下,人工去包装每个方法就不现实了,需要借助工具来完成包装函数。本文不再介绍第三方工具的使用方法。
实践
我们团队在前端实现几何算法时,经常需要大规模的数学计算,这促使我们去尝试WebAssembly 这项技术。我们将某个计算密集型的前端模块用 C 实现并编译为 WebAssembly,在 JavaScript 端调用,类似上述 Demo。但是,应用 WebAssembly并没有带来性能上的优化,甚至大部分情况下比原始的 JavaScript模块还要慢很多。这是什么原因?
前端维护的几何模型包含很多面(face),我们首先尝试将所有面依次传入WebAssembly 进行计算。在上述 Demo 中体验的数据转换到共享内存是不是很麻烦呢?通过性能分析可以定位:正是因为数据转换存在额外开销,而对每个面执行这样的转换过于频繁,导致性能不升反降。下图红色箭头部分均涉及数据转换,每个面都要进行一次输入数据转换和输出数据转换。而 JavaScript 不需要数据转换时间,只需要计算时间。
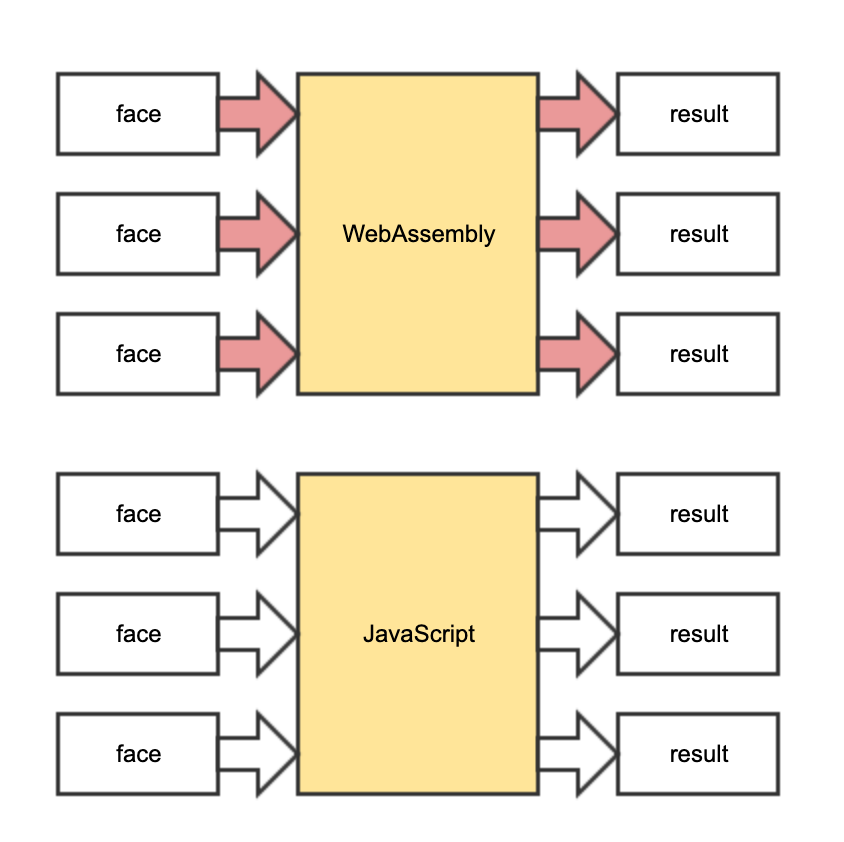
在这种情况下,应该怎么办?得出 “WebAssembly 在实际应用中比 JavaScript慢” 的结论然后放弃使用 WebAssembly 吗?当然不是。WebAssebmly作为一项高性能技术(高性能使得它相对来说偏向底层一些),应当让它多做并且集中地做自己擅长的事情:计算。为此,我们尝试用批处理的方式节省多次数据转换到共享内存的开销。我们在C 端增加一个批处理接口,同时在 JavaScript 端以批处理形式进行 I/O访问。即:这个批处理的输入是面的数组,输出也是面的数组。这样每次调用WebAssembly 可以处理一组面,大幅度降低数据转换的频率。
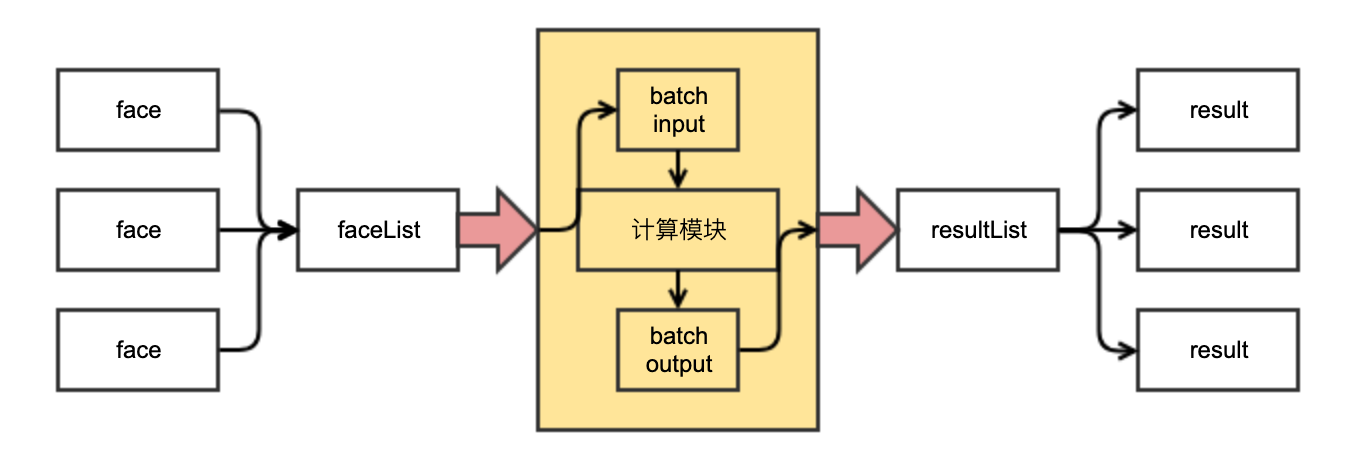
除去批处理之外,还应当注意编译选项增加编译器优化 emcc-O3。优化有若干等级,详见Emscripten官方文档优化代码部分。经编译器优化后的代码运行效率必然更高,但相应地编译时间也会更长,适合用于release 版本。
此时,WebAssembly 的优势才得以展现。经统计,应用 WebAssembly之后,计算效率是 JavaScript 实现的库的 2.5-6.5倍。该结论亦符合他人已进行过的实验的结论。以这样的思路,还可以序列化后输入、输出后反序列化。在数据结构较复杂时(比如多层嵌套的引用结构),串化比数组批处理更快。
结论
实践中,我们可以总结出一些经验:
- 做好性能分析,对高频次操作制定批处理策略如果直接应用 WebAssembly 不能提升性能,不要急着放弃,先分析一下应用情景再试试看。其实,WebAssembly团队开发者表示在多次寻址(复杂引用类型数据结构)时I/O开销大是个已知的问题,并且已知有优化空间,有望在未来版本中逐步降低这部分开销。
- 尽量避免联调,应先将原生代码单元测试做充分,保证原生代码的稳定当要在C端做修改时,我们不建议对原有C代码直接进行修改(edit),仅添加(append)一些批处理或串化等包装方法。不仅因为 WebAssemly 与 JavaScript 之间调试非常困难,更应保持原有程序模块的纯净。虽然 WebAssembly团队开发者表示,在浏览器端调试原生代码的需求在未来可能会得到改善,但保持两端稳定、避免耦合仍然是合理的做法。
- 注意回收内存,尤其是共享内存 demo 中不回收可能看不出什么问题,但实践中不回收会产生严重的问题。不仅 C 端需要回收计算过程中产生的内存申请, JavaScript 端也应注意回收共享内存(Module._free(addr))。
总的来说,WebAssembly 作为一项高性能、相对底层的技术,在实践中需要根据它的特性做出一些妥协。如何很好地包装这些妥协、不对业务层展现,可能会成为最复杂的一个部分。
注:本节提及的 WebAssembly 团队开发者传达的信息来自于 2018QCon 前端专场演讲《WebAssembly领进门及未来发展》(朱立旻@MicroSoft)现场答疑环节。
评论系统未开启,无法评论!